
This tutorial is intended for users who have access to the Ohio Supercomputer Center (OSC) for research purposes but who are not familiar with conducting research in a supercomputing environment. It gives an overview of the resources available from OSC and the structure of the OSC computing environment, methods for connecting to OSC, job submission, software installation, and help desk requests.
An Overview of OSC
The term “supercomputer” is somewhat vague, but what it typically means in today’s context is actually a supercomputing cluster, or a large collection of high-powered servers connected via a local network. Clusters allow users to run computationally intensive, parallelizable tasks in a single environment. To illustrate the concept, I have provided an image of one of OSC’s retired clusters, Oakley, from the OSC website.
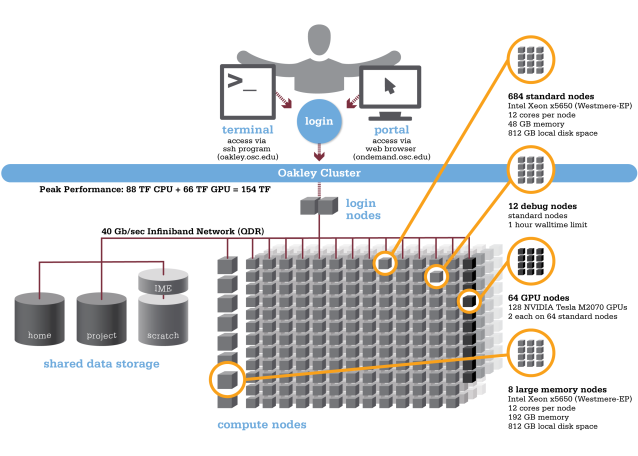
In a supercomputing center like OSC, many users share these resources at once, and resources (nodes, memory, and time) are allocated to users as users request them. You do this by submitting jobs (discussed later). When you submit a job, you request the resources you need. When those resources are available on the cluster you are using, your job will run.
Computing Clusters
OSC has 3 clusters: Owens, Ruby, and Pitzer. To decide which of these clusters best meets your needs, check the specifications of each from the OSC website. Depending on your research, you may want to think about the type of network connections used or how many GPU’s are available. You may also want to browse the software list to determine which clusters contain the software you need.
Note: While not all clusters have the same resources, user files are mirrored across all clusters. This means that, if you are using Owens and Owens is unavailable due to periodic system updates, you can use another cluster until Owens is available again.
Login Nodes and Compute Nodes
Most of the nodes in any OSC cluster are compute nodes, with a few login nodes. The difference between the two is mainly this:
- Login nodes are used only for logging in and for very basic tasks, like moving or deleting files. There are only a few of them because the tasks performed on them are not intensive, so many users can share only a few nodes.
- Compute nodes are used for intensive computational tasks. All of your work should be done on compute nodes, not on login nodes.
When you connect to OSC (no matter which method you use), you are connecting to a login node. The only way to access a compute node is by submitting a job. Any work you do on OSC must be done within a job – otherwise, you risk putting a heavy workload on the login nodes. If you do this, any script you run will be killed almost immediately, and you will receive an e-mail from the OSC administrators reminding you to never do that again.

File Systems
All OSC clusters have the same file systems, described below.
- /fs/home is the file system you are directed to automatically when you log in, and it is organized by user ID. You can store data and output files there, but your collaborators won’t be able to access them.
- /fs/project is a file system organized by research project ID. To get to your project folder, you will need to navigate to /fs/project/. Storing your files here makes them available to your collaborators.
- /fs/scratch is a large file system for temporary storage and is available to everyone. Use it if you need to share files with someone who does not have access to your project folder or if your files are too large to fit in your project folder.
Connecting to OSC
Personally, I prefer to use the command line for most of the work I do, but many users like the look and feel of a GUI. If you prefer using a GUI, access OSC through the OnDemand Web Portal. If you prefer working from a command line, use PuTTY (for Windows users) or SSH (for Mac or Unix users).
Using the OnDemand Web Portal
OnDemand is a web-based service run by OSC administrators for accessing OSC using a GUI (No installation required). OSC has a tutorial for using OnDemand. Note that, instead of using CILogon, you will want to choose “Log in with your OSC account”. You will be asked to register your username and password the first time you log in.
Using PuTTY (Windows)
To connect using Windows, use PuTTY. If you haven’t used PuTTY before, just download it and it’s ready to use! Once you have PuTTY installed, configure PuTTY to connect to OSC as shown below (the example below is for the Owens cluster). Other than what is highlighted, no changes need to be made to the settings.

Note: I have saved this connection under the name “Owens” by entering “Owens” under Saved Sessions and clicking Save. If you do this, it saves all information for future logins. You can select Owens and click Load rather than entering everything again.
Using SSH (Mac / Unix)
From your terminal, simply use one of the following commands, depending on which cluster you wish to use.
ssh "user-id"@pitzer.osc.edu
ssh "user-id"@owens.osc.edu
ssh "user-id"@ruby.osc.edu
Submitting Jobs
Here we are…the most important part of the tutorial! Once you have logged into your cluster, you will need to submit your job so that your code can run on the compute nodes. When you submit a job, you need to think about the following things:
- How many nodes you will need. This is going to depend on how you’ve parallelized your code. To run on multiple nodes, you will need to use a parallelization package that supports MPI or OpenMP in your code. Examples of this are Rmpi and snow in R, and mpi4py in Python.
- How much memory (or processors) you will need. If your program uses threading, you will need to request processors accordingly. Note that, in addition, the amount of memory allocated for you is proportional to the number of processors you request. For instance, standard Owens nodes have 28 processors and and 64 GB memory, so requesting 4 processors on Owens will allow you to use 9 GB memory. If you need to use more than 64 GB, you can request a large memory node by requesting as many processors as the large memory node contains (e.g. 48 on Owens). Note: If you are using multiple nodes, you must request all processors for each node.
- How much time you will need. It is best to overestimate on your first run. Then, you can see how much time the job actually takes interactively or using a batch job by checking the log files.
There are two types of jobs that you can run: interactive jobs and batch jobs. You can create these yourself or (if you are using OnDemand) you can use the Job Composer templates provided by OnDemand as shown in the image below. The next two sections describe the types of jobs and how to create them without using templates.

Interactive Jobs
An interactive job allows you to connect to the compute node and interactively run tasks. This approach has the following advantages over running in batch mode:
- You can catch bugs as soon as they occur.
- You can view output in real time.
- If you prefer running code line-by-line (such as with an R or Python interpreter), you can do that.
However, note that an interactive job does not keep running in the background when you close your connection to the cluster. For time-intensive tasks, it is not a good choice. Sometimes, it can also be inconvenient when a job is queued, because you should periodically check whether it has been dequeued so that you can run your tasks.
To run an interactive job, issue the following command.
qsub -I -l nodes=4:ppn=28 -l walltime=3:00:00 -A PAS0001
Here, the request is for 4 nodes with 28 processors each (To run on large memory nodes, we could have requested 48 processors each). The interactive job will run for 3 hours, and resources will be charged to project PAS0001.
Batch Jobs
In a batch job, all of your tasks are run from a shell script, which you must create. Batch jobs have the following advantages:
- They will continue running even after you close your connection to the cluster, making them a good choice for time-intensive tasks.
- You do not need to check whether a job has been dequeued before running anything. Since your commands are in a script, they will run as soon as the job is dequeued.
- Putting your commands in a script can help you to better organize your code.
For a batch job, you should create a shell script, e.g. myscript.sh, with the following format.
#PBS -l nodes=4:ppn=28 #PBS -l walltime=3:00:00 #!/bin/bash for i in 0 1 2 3 4; do echo $i Rscript some_r_script.r $i done
Here, we are again requesting 4 nodes with 28 processors each and 3 hours of runtime. This is specified in the #PBS directives. The rest of the code is an example: it loops through the numbers 0 to 4, prints them out, and calls an R script. This is meant to illustrate how you can use a shell script for simple looping and branching, input and output, and running code.
Now that you have created your script, you will need to submit it. To do this, run:
qsub -A PAS0001 my_script.sh
After your script completes, it will save your console output to a file called my_script.sh.o."some-number" and any errors to my_script.sh.e."the-same-number".
Checking Job Status
To check the status of a job, run the following command:
qstat -u "user-id"
If you have a job running, your output will look something like this:
Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time ----------------------- ----------- -------- ---------------- ------ ----- ------ --------- --------- - --------- 4723639.owens-batch.te serial STDIN 86768 1 28 -- 03:00:00 R 00:00:06
This tells us the job ID, that the job is running from STDIN (i.e. it is an interactive job), that it is running on one node with 28 cores, and that it has been running for 6 seconds. Instead of R, jobs that are queued will show Q as their status. Jobs that have recently completed will show C.
Deleting a Job
To delete a job, you must first obtain its ID, which can be done by checking the job status as shown above. Once you have the ID, run:
qdel "job-id"
In this case, the job ID is 4723639.
Transferring Files
To/From a Local Machine
Using OnDemand
To use OnDemand for file transfers, please see this tutorial from OSC.
Using SFTP or SCP (Mac / Unix)
SCP is generally faster than SFTP, but SFTP allows for file management on the remote server, such as file deletion and creation of directories. Learn more about the differences here.
To use SFTP for file transfers, connect to the OSC SFTP server as shown:
sftp "user-id"@sftp.osc.edu
To use SCP for file transfers, use the OSC SCP server as shown below. The first command is for transferring from the SCP server to your local directory, and the second is for transferring from your local directory to the SCP server.
scp "user-id"@scp.osu.edu:"your-file.txt" "your-local-directory"
scp "your-file.txt" "user-id"@scp.osu.edu:"your-remote-directory"
Using FileZilla or WinSCP (Windows)
To connect via FileZilla or WinSCP, you will need the same connection information as you used for the PuTTY connection, but you will use the SFTP server instead of the cluster name for FileZilla and the SCP server for WinSCP. Here is an example using FileZilla.

Downloading from Online
One option for retrieving files from online is to download them to your local system and transfer the files using one of the methods above. But this isn’t very efficient, especially if you are downloading large data files.
My favorite method for downloading data from online is to use wget. For example:
wget https://www.encodeproject.org/files/ENCFF001CUR/@@download/ENCFF001CUR.fastq.gz
This downloads a 1.41 GB file from the ENCODE Consortium. For me, it downloads at a speed of 29.7 MB/s.
If you want to obtain data from GitHub and are familiar with Git commands, you can also clone a repository from the OSC command line using git clone . Git is automatically installed on the OSC clusters, so you don’t need to worry about installing it.
It is a good idea to check whether your download was successful. If the file you are downloading has an md5 checksum, you can use that to verify your dowload. For instructions on using md5 checksums, see this tutorial.
Using Software
Available Software
Each cluster on OSC has software pre-installed that you can use. So before trying to install new software yourself, check whether it is already available using:
module spider "name-of-program"
An example of the output for R would be:
---------------------------------------------------------------------------------------------------------------------------------------------------------
R:
---------------------------------------------------------------------------------------------------------------------------------------------------------
Versions:
R/3.3.1
R/3.3.2
R/3.4.0
R/3.4.2
R/3.5.0
R/3.5.2
Other possible modules matches:
amber arm-ddt arm-map arm-pr blender darshan espresso express freesurfer gromacs hdf5-serial homer hyperworks libjpeg-turbo ...
---------------------------------------------------------------------------------------------------------------------------------------------------------
To find other possible module matches execute:
$ module -r spider '.*R.*'
---------------------------------------------------------------------------------------------------------------------------------------------------------
For detailed information about a specific "R" module (including how to load the modules) use the module's full name.
For example:
$ module spider R/3.5.2
---------------------------------------------------------------------------------------------------------------------------------------------------------
Note that this also tells you which versions are available. Sometimes, the version of software you want to use is available on OSC, but there is another version loaded by default. To load the version you want, just use module load. For example, let’s say that you want to use version 3.5.2 of R, but 3.5.2 is not the default.
Then, you can run:
module load R\3.5.2
Configuring Paths
Setting your $PATH environment variables can be useful in a Unix environment. It allows you to simply type the name of the software or package you wish to use, without specifying the full path. In OSC, you do this by modifying two files: .bashrc and .bash_profile. These can be found in your /fs/home directory. Below is an example of .bashrc file content:
PATH=$PATH:$HOME/.bds
PATH=${PATH}:$HOME/gosr/bin
PATH=${PATH}:$HOME/Samtools/bin
PATH=${PATH}:$HOME/FastQC/
PERL5LIB=$HOME/bioperl-1.2.3
PERL5LIB=${PERL5LIB}:$HOME/ensembl/modules
PERL5LIB=${PERL5LIB}:$HOME/ensembl-compara/modules
PYTHONPATH=$HOME/pythonmodules/pysam-0.7.5/lib/python2.7/site-packages
PYTHONPATH=$PYTHONPATH:$HOME/usr/local/anaconda/anaconda2/pkgs/
PYTHONPATH=$PYTHONPATH:$HOME/pythonmodules/gosr/lib/python2.7/site-packages
Here, I have added system paths, Perl-specific paths, and Python-specific paths. Simply add a similar line to both the .bashrc and .bash_profile files to include any additional path. You will need close and reopen your connection to the cluster before these changes can take effect. Note: It is important to modify both files. One is used for the login node, and the other is used for the compute node. Ideally, you want them to be consistent.
Installing Software and Packages
Installing software on OSC is not as simple as on a Unix system on which you are the root user. You do not have sudo access, so you are limited to user installations. For example, I often use the following for python modules:
pip --user "package-name"
If there is software or a package you wish to install that requires root access, you will need to contact the OSC Help Desk.
Support
To request support, contact oschelp@osc.edu with a description of the problem you are facing, and include your user ID. The help desk usually responds quickly.

{kind=link}
One thought on “Ohio Supercomputer Center Tutorial”